
Since my cPanel shared hosting provider supports node.js hosting, installing a federated wiki site beside the usual Softaculous packages is an option. The app requires node.js, and there is a variety of ways to deploy that.
In 2014, I had installed a federated wiki site on Openshift, but then didn’t maintain it as other priorities surfaced. The site is now available at http://wiki.coevolving.com, and the prior content has been restored.
The installation isn’t a one-button procedure. However, an administator comfortable with opening an SSH terminal onto your shared hosting account should be able to follow the steps below. (If you have problems, the federated wiki community hangs out in a room on matrix.org).
A. Creating a Subdomain
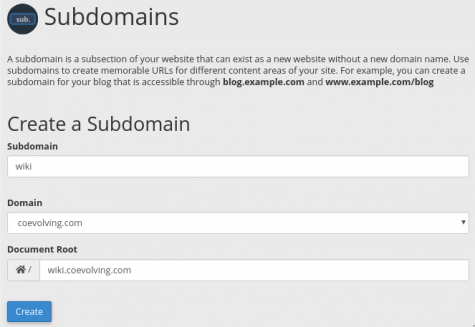
(1) Through your browser, from cPanel … Domains … , create a Subdomain.

- As an example, I can create a Subdomain wiki in the Domain coevolving.com, that will actually be stored in my Home (Document Root) as a wiki.coevolving.com directory.
B. Installing Federated Wiki
(2) From cPanel … Software … Setup Node.js App.

- In the Web Applications list, Create Application. As an example, set:
-
- Node.js version: 10.11.0
- Application mode: Production
- Application root: wiki.coevolving.com
- Application URL: wiki.coevolving.com
- Application startup: app.js
-
- (If you leave the Application startup field blank, app.js automatically fills in as the default)
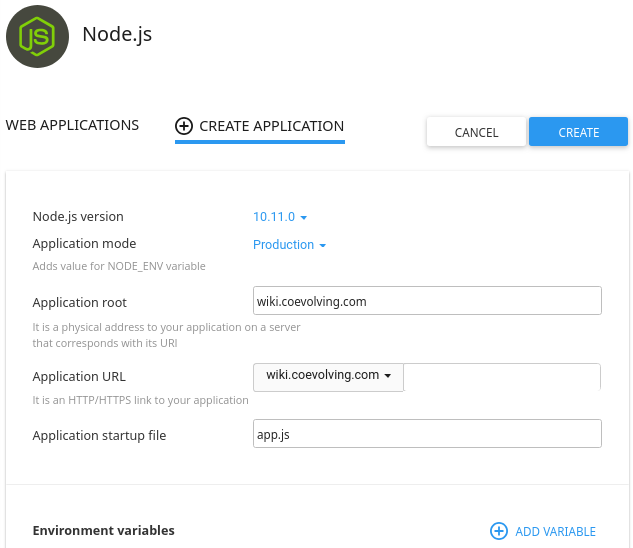
- At this point, the node.js environment is not yet activated, as the package.json has not yet been downloaded, and the Run NPM Install button is greyed out.
Since my cPanel shared hosting provider supports node.js hosting, installing a federated wiki site beside the usual Softaculous packages is an option. The app requires node.js, and there is a variety of ways to deploy that.
In 2014, I had installed a federated wiki site on Openshift, but then didn’t maintain it as other priorities surfaced. The site is now available at http://wiki.coevolving.com, and the prior content has been restored.
The installation isn’t a one-button procedure. However, an administator comfortable with opening an SSH terminal onto your shared hosting account should be able to follow the steps below. (If you have problems, the federated wiki community hangs out in a room on matrix.org).
A. Creating a Subdomain
(1) Through your browser, from cPanel … Domains … , create a Subdomain.
- As an example, I can create a Subdomain wiki in the Domain coevolving.com, that will actually be stored in my Home (Document Root) as a wiki.coevolving.com directory.
B. Installing Federated Wiki
(2) From cPanel … Software … Setup Node.js App.
- In the Web Applications list, Create Application. As an example, set:
-
- Node.js version: 10.11.0
- Application mode: Production
- Application root: wiki.coevolving.com
- Application URL: wiki.coevolving.com
- Application startup: app.js
-
- (If you leave the Application startup field blank, app.js automatically fills in as the default)
- At this point, the node.js environment is not yet activated, as the package.json has not yet been downloaded, and the Run NPM Install button is greyed out.



